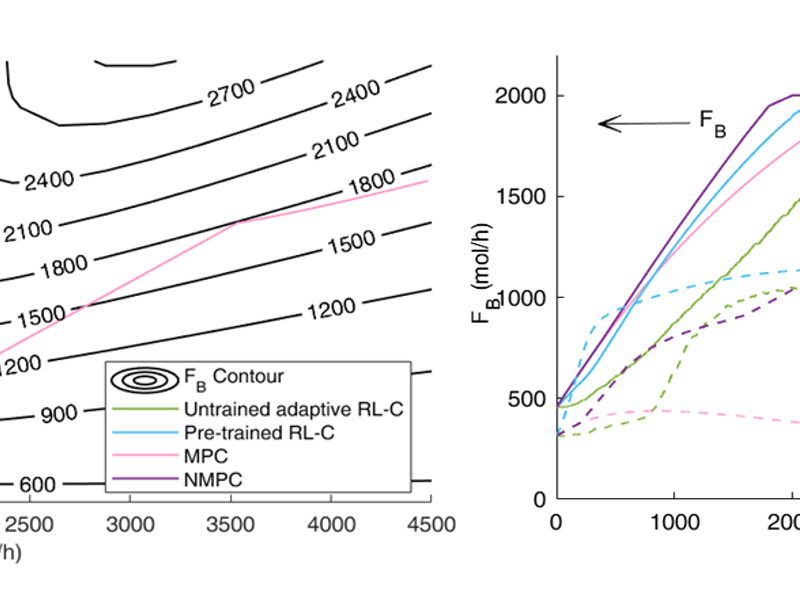
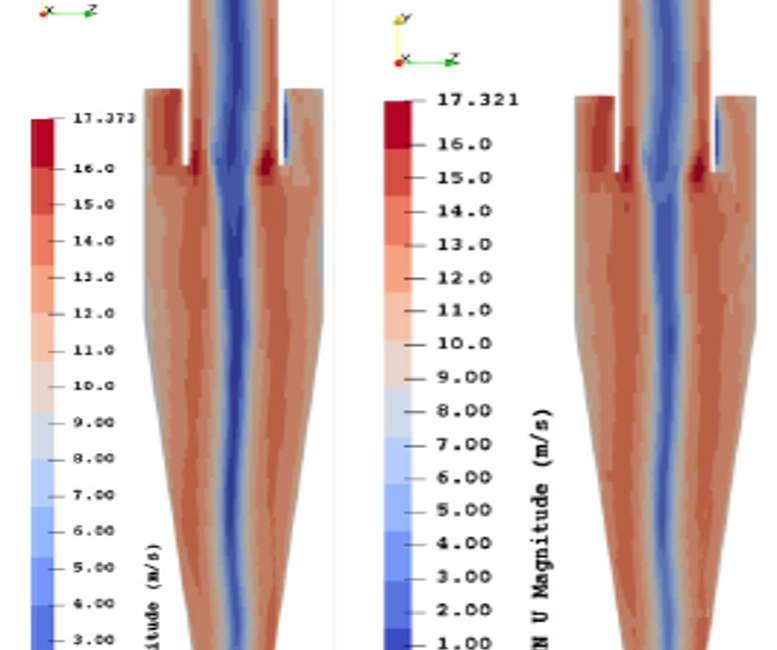
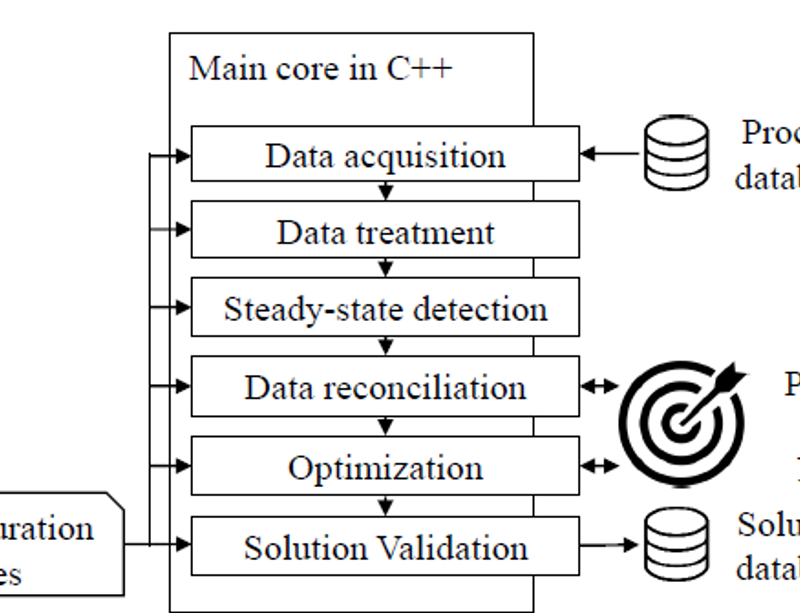
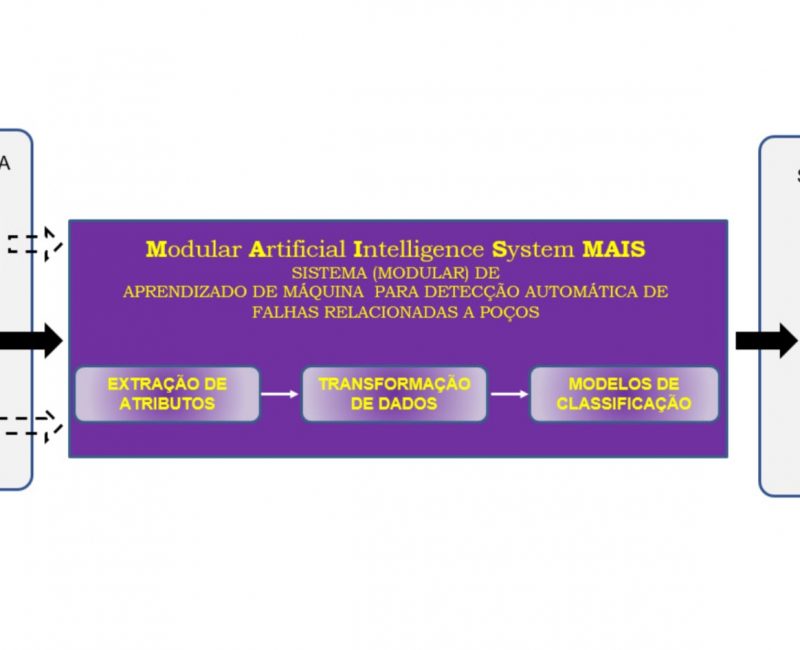
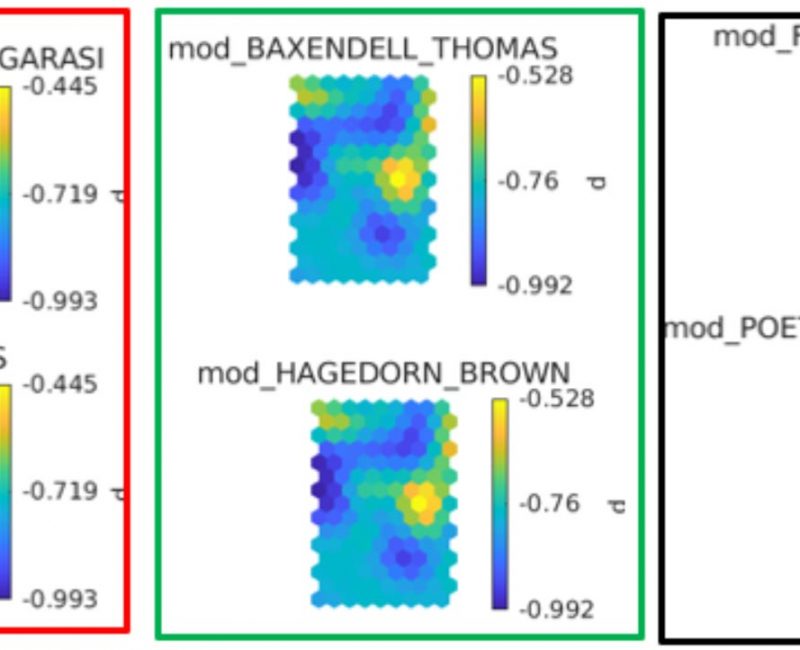
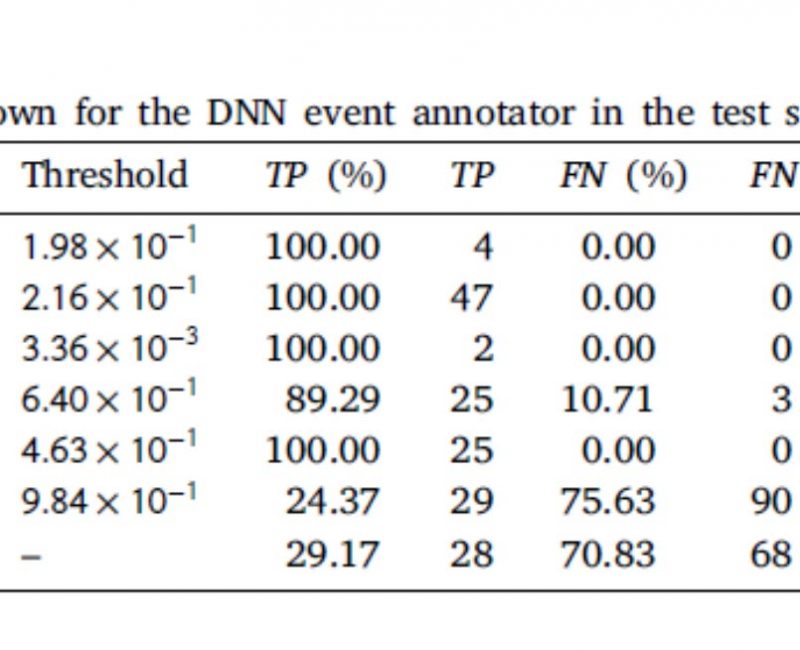
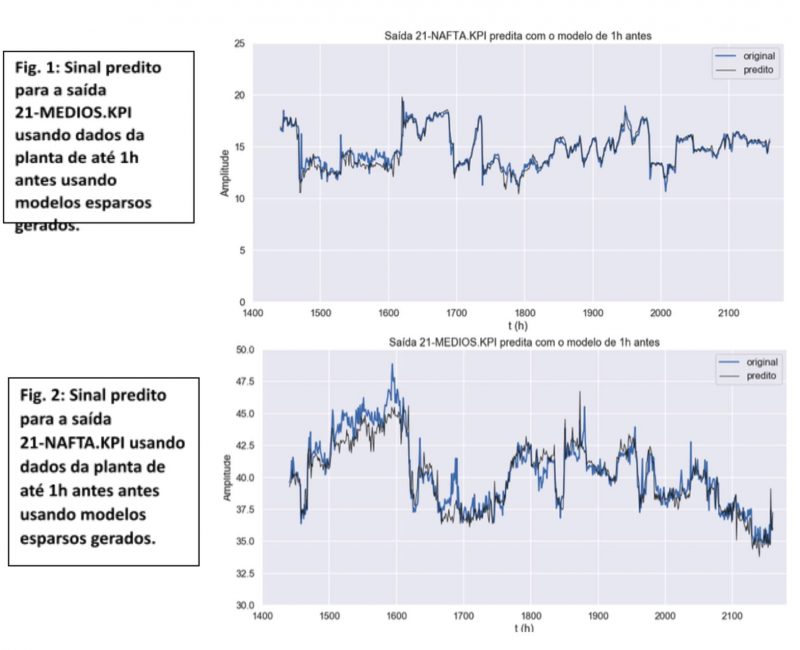
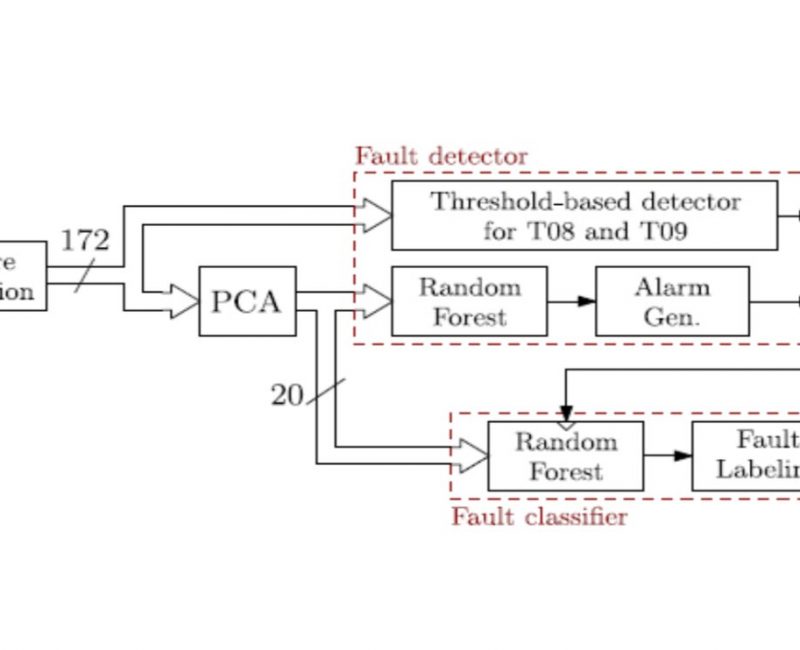
20 nov
Categories Artigos
Over the last decades, oil and gas companies have been facing a continuous increase of data collected in unstructured textual format. New disruptive technologies, such as natural language processing and machine learning, present an unprecedented opportunity to extract a wealth of valuable information within these documents. Word embedding models are one of the most fundamental units of natural language processing, enabling machine learning algorithms to achieve great generalization capabilities by providing meaningful representations of words, being able to capture syntactic and semantic features based on their context. However, the oil and gas domain-specific vocabulary represents a challenge to those algorithms, in which words may assume a completely different meaning from a common understanding. The Brazilian pre-salt is an important exploratory frontier for the oil and gas industry, with increasing attractiveness for international investments in exploration and production projects, and most of its documentation is in Portuguese. Moreover, Portuguese is one of the largest languages in terms of number of native speakers. Nonetheless, despite the importance of the petroleum sector of Portuguese speaking countries, specialized public corpora in this domain are scarce. This work proposes PetroVec, a representative set of word embedding models for the specific domain of oil and gas in Portuguese. We gathered an extensive collection of domain-related documents from leading institutions to build a large specialized oil and gas corpus in Portuguese, comprising more than 85 million tokens. To provide an intrinsic evaluation, assessing how well the models can encode domain semantics from the text, we created a semantic relatedness test set, comprising 1,500 word pairs labeled by selected experts in geoscience and petroleum engineering from both academia and industry. In addition, we performed an extrinsic quantitative evaluation on a downstream task of named entity recognition in geoscience, plus a set of qualitative analyses, and conducted a comparative evaluation against a public general-domain embedding model. The obtained results suggest that our domain-specific models outperformed the general model on their ability to represent specialized terminology. To the best of our knowledge, this is the first attempt to generate and evaluate word embedding models for the oil and gas domain in Portuguese. Finally, all the resources developed by this work are made available for public use, including the pre-trained specialized models, corpora, and validation datasets.